

The Ultimate Guide to Unit Testing With dbt
The Ultimate Guide to Unit Testing With dbt
How to become a DataOps unicorn with test-driven development


Do your stakeholders come to you and tell you there’s something wrong with their reports?
Do you feel anxious when you need to modify the logic of a complex dbt model you haven’t touched in months?
Do you often find yourself in a situation where your new model doesn’t comply with the requirements after you spend hours working on it?
Believe it or not, most analytics and data engineers would answer “Yes” to these questions immediately. The chances are your answer is positive, too.
Let’s be honest, you have a severe problem!
You work slowly and produce buggy code that doesn’t align with colleagues’ needs. People can’t rely on you to provide quality work and don’t trust you. You are a liability.
But fret not! There’s a well-known process explicitly designed to target these issues. Test-driven development with unit tests is a practice widely used by software engineers but not popular among data professionals.
By implementing unit tests, you will improve the communication with your partners in the business. You will also be more confident and iterate faster on your tasks. You will be among the few world-class data professionals who address issues with their models upfront.
In the last issue of Data Gibberish, you learn what unit tests and TDD are. In this article, we are discussing:
Short recap of the previous article;
What components unit test need;
Step-by-step tutorial on implementing unit tests with dbt;
Improving your DataOps process.
Reading time: 10 minutes
Recap
As usual, I strongly recommend reading my last article. Yet, here's the essence:

You, as most dbt community members, only test data in production. This means you learn about mistakes after you load faulty data in our warehouse. This practice is slow and expensive, but most importantly, it impacts your people’s trust in you.
Unit tests are specific kinds of tests that don't exist natively in dbt. They ensure that you comply with your requirements and that your models’ behaviour does not break in the future.
You can revert your process and test before you start writing code. This process is called Test-driven development, or TDD for short. It’s steps on unit tests but also helps you clarify specifics and avoid design flaws upfront.
I wrapped up my last article with a promise to show you how you can implement unit tests in our dbt projects. And here we are.
Overview
I want to spread the word about unit tests as much as possible and give you a complete step-by-step plan for implementing unit tests with dbt. This is not yet another talk about theory; this is a story. It’s precisely what allowed us to move from ETL to ELT stack and processes in under six months.

But wait, there's more! Random snippets of wisdom and code are not enough here. I added unit tests to the famous Jaffle Shop project from dbt Labs, so you can try everything out directly without copying and pasting the code from the article.
https://github.com/ivanovyordan/jaffle_shop
Here's what you'll do if you want to steal my unit test blueprint today:
Create a CI dbt profile;
Install dbt Utils;
Add Dummy Data;
Add Expectations;
Run the Tests.
Now, let’s step even further. Consider this issue of Data Gibberish as a hands-on workshop on unit testing with dbt.
Let's get this show on the road!
Milestone 1: Create a CI dbt Profile
Most dbt projects I've seen have two targets:
devfor your local development environment;prodto build your production data and make it accessible to the world.
Effective unit tests require an isolated environment. This isolation means no external factors are affecting your models' behaviour. They need a lab environment if you wish.
To create that environment, open your profiles.yml file (usually ~/.dbt/profiles.yml) and add a ci target to your project. You can find the sample profiles file in my fork of the Jaffle Shop project. And this is what the CI target looks like:
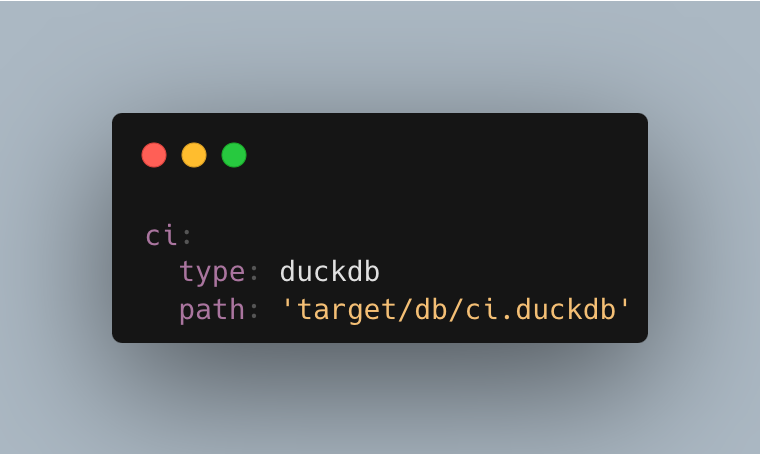
In this case, I work with a DuckDB database. This means you can run the tests for free using a single file. If you work with a proper warehouse, say Snowflake, you can create a personal testing schema next to your dev schema.
Milestone 2: Install dbt utils
Before working on your unit tests, you have to install the dbt utils plugin.
dbt utils is a package with some handy macros and tests. For this step, you need the equality test. However, I have never seen a dbt project without this plugin, and I firmly believe it's a must-have no matter what.
To install it, add this line to your packages.yml file. Here's what my Jaffle Shop file looks like:

Once you save that file, open your terminal and run this command in your project's folder:

Now, buckle up because this may be pretty challenging.
Milestone 3: Add Dummy Data
You can now start with generating our mock input. But this is not just a random subset of your data. You need to be strategic when working on that piece. Collect the requirements and understand what your data means.
As I told you, you should not work with your production data. Instead, you need just a handful of handcrafted examples. Think about every corner case and manually create your version of the input data.
For example, your Jaffle Shop customers can split their orders among different payments.
And here’s our dummy data with order 9 split into two payments.
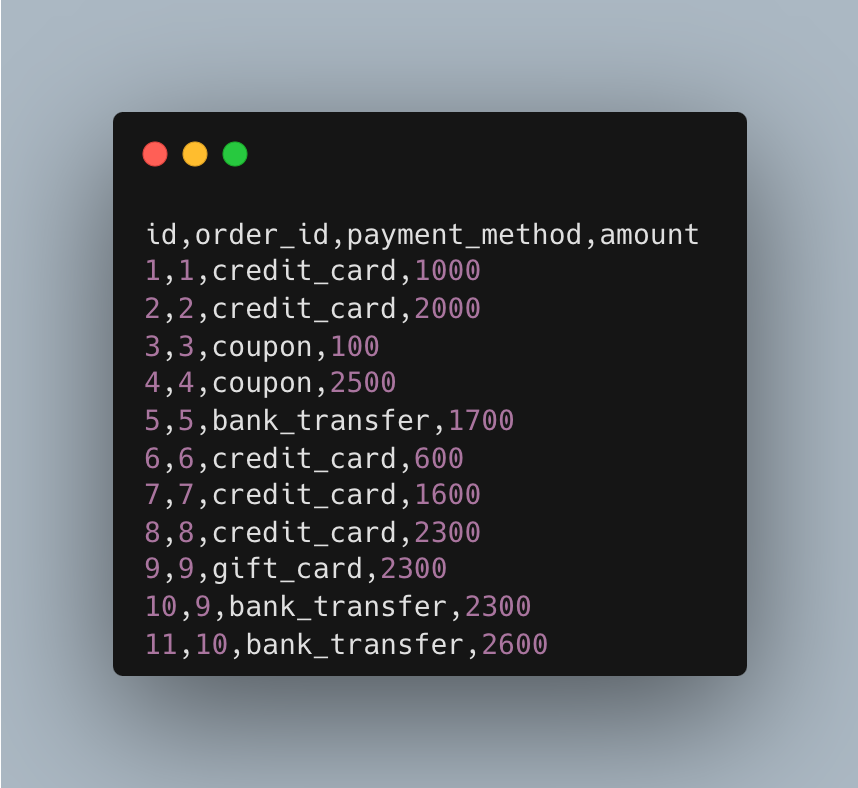
You need to create a test directory in your data folder or wherever you store seeds and save your fixtures as CSV files. But remember, your seeds must have the same names as your raw tables. And again, you can find the actual file on GitHub.
But we are not through yet. There's one problem you need to handle with your mock data.
If you run dbt seed, you will create tables in your data warehouse with the names of those files. You want this data to be available only when you run your tests and not mess with your data on production. To do that, you'll benefit from the ci profile from the previous section.
Open your dbt_project.yml file and add the following snippet (which you can find in the repository):

Here, you do two things:
You enable the standard “production” seeds in all cases except when you run CI checks;
You enable dummy raw data only when the
citarget is active.
And that’s it with the mocks, but let me be clear:
What you did may look easy now, but it's more complicated in real life. Crafting proper fake data is the hardest part of building your unit tests. Not just because exploratory data analysis (EDA) requires a lot of time but also because sometimes you need to keep track of related seed records. Yet, that effort pays out over time by reducing debugging time and simplifying the improvement process.
Anyway, there's just one final step before you can run your tests. The next part is still complicated but slightly less so.
Milestone 4: Add Expectations
Expectations are the meat and potatoes of unit testing. As I told you in the last issue of the newsletter, the idea of unit tests is to run your models using the fixture seeds and then compare the results with your expectations.
Here, you need to answer one question:
What should the result of your transformation look like?
Let's take a look at the Jaffle Shop requirements for the orders. Here, you need one row per order, with dedicated columns for each payment method and one more column for the grand total.
You can easily write a static query that generates the result of these requirements if you consider the fixtures you created in the last step. In fact, you can do that even before working on your model, but more on that later.
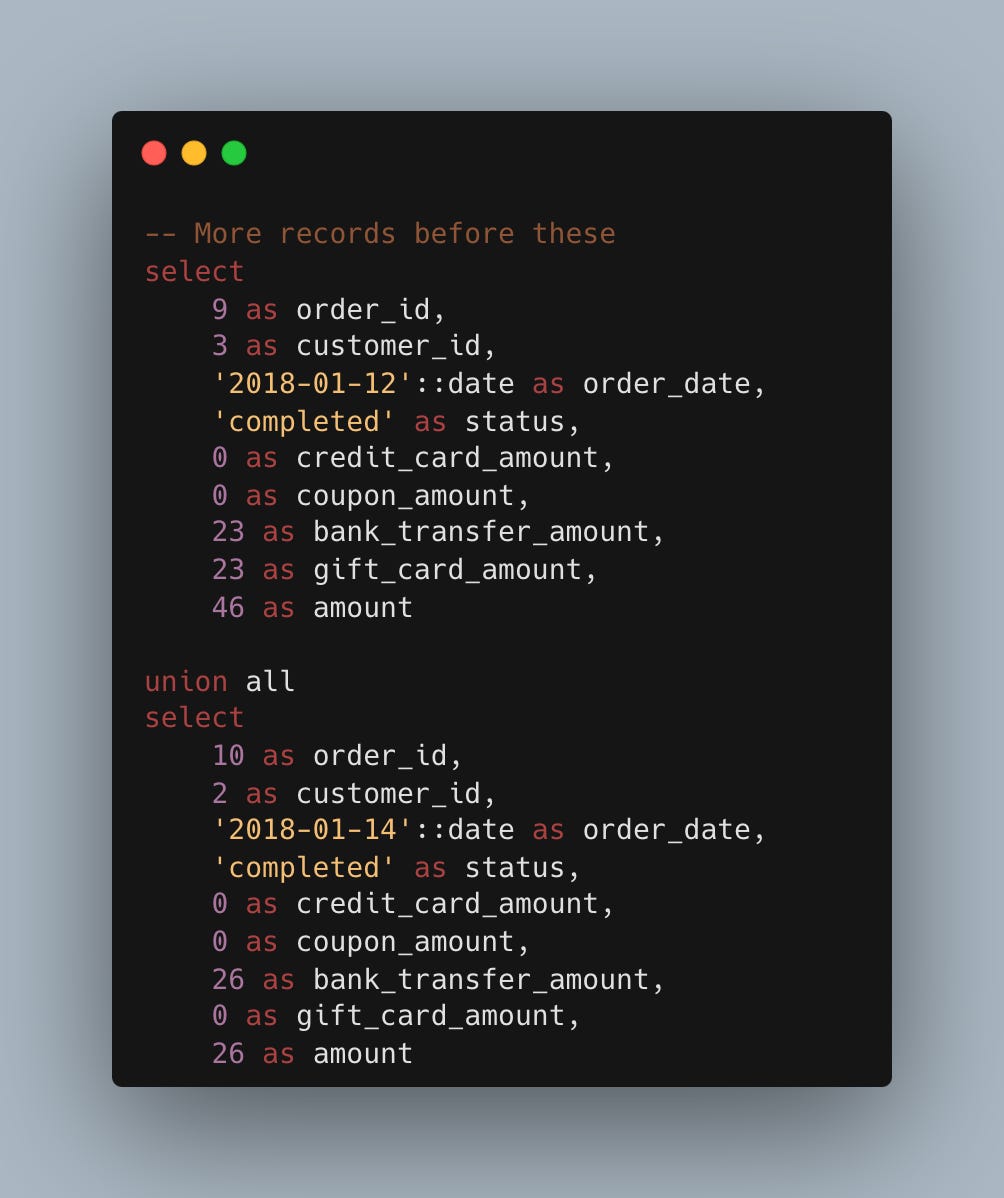
Create a test folder in your models directory, then create one SQL file for each model you wish to test. Use the model's name and prefix it with the string test_, so orders.sql becomes test_orders.sql.
As always, you can grab the entire expectation from my test_order.sql file.
Now, you have the same problem we had with the seeds. If you run your project, the expectation will materialise in your production environment as a table.
To address that, you can reuse the same snippet from the previous section and enable your expectation only when running against the ci profile. You can also prevent that model from being stored in your warehouse for maximum efficiency.
Add your configuration to the models section in your dbt config, as I did here:
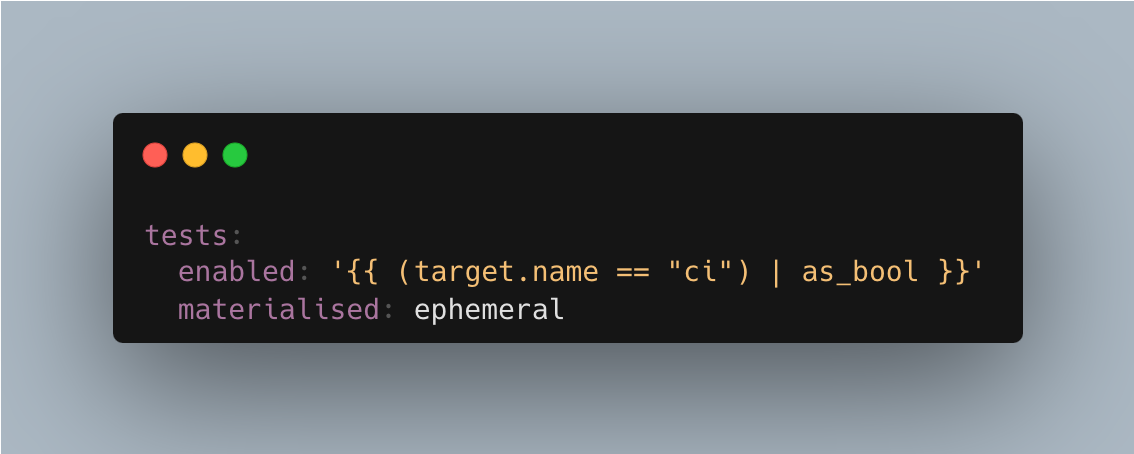
Congratulations! You have all the components for your unit tests. Now, it's time to link these pieces and run the tests.
Milestone 5: Run the Tests
Once you've all the ingredients in place, you need to stitch them to the model's configuration.

Here, you invoke the equality test from dbt utils and compare the result of your stg_orders with the test_stg_orders expectation. The equality macro also lets you list the columns you wish to compare. In my experience, this feature is an absolute saviour when your models have dynamic fields—say, build timestamp—that you want to skip.
And because you enabled the fixture and the expectation only when the ci dbt profile is active, it makes sense to do so with the test, too. But anyway…
Drumrolls, please!
Now, you will run the test and see the fruits of your effort. To do that, you just have to build (seed + run + test) your model using the ci profile.

If you did everything correctly, you should see some green equality tests in your dbt output, among everything else. In the same way, if you skip the ci target, you won't run the seeds or the tests.
Now, let's recap.
Recap
Crafting practical unit tests is a challenging task. You need to know your data and create your fixtures—CSV files imitating your raw data—and expectations—static SQL files representing what you imagine your models need to do.
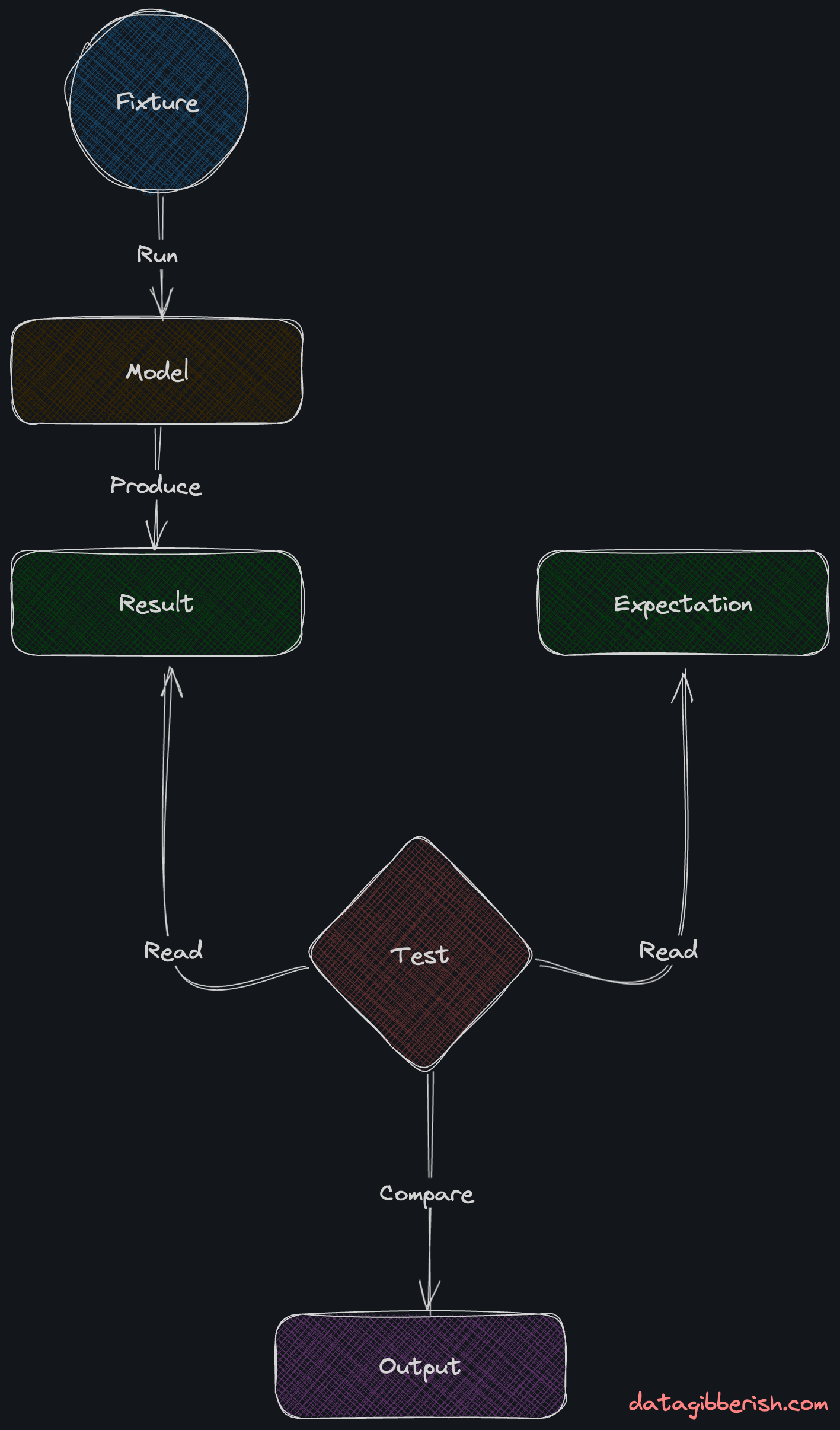
To build a model, you need to seed your dbt project with the fixture, which would create an authentic raw data table.
Then, you run the model, feed it with that dummy data, and build a table as if you did that with actual production data.
Last, you run the test, which compares the result table with your expectation.
Now, I know what you are thinking:
All this unit testing will take a ton of effort in a real-world project!
And you are right! Unit tests are time-consuming. You need to think strategically and know what you want to achieve. You must spend enough time creating realistic tests, and your peers or stakeholders may not see the point.
Yet, you buy confidence in your code for that investment in time. You are confident you build something that aligns with your client’s needs and that your updates do not break existing logic. The long-term result is a much shorter feedback loop and improved trust.
It’s your turn now!
Next Level DataOps
Now that you understand unit tests well, it's time to step, not one, but two steps further.
Step one is to run your unit tests with every Pull Request. That way, you can ensure people won’t break your models when they work on seemingly unrelated models.
Step two is to embrace test-driven development. Start writing your tests before the code. Run them when you finish with a model. Even run them automatically on every save if you need to. Unit tests run blazingly fast, so they won’t slow you down.
Now, let me tell you a secret.
Can you guess how many data or analytics engineers practice unit testing or TDD?
According to the official statistics, around 40% of all dbt projects have tests. This means that just by implementing basic dbt tests, you are ahead of 60% of data professionals. I don’t have stats about unit tests, but I bet the percentage of people who practice TDD in the dbt community is in the single digits of those 40%.
So, using unit tests and TDD will not just put your project on an entirely new level of stability. You can also brag that you use top-notch software engineering practices. You automatically become a DataOps unicorn.

Did you enjoy that piece? Follow me on LinkedIn for daily updates.

In your example your source is a seed, what if my source is a {{ source('') }}, how do you mock it in this case?
Very awesome