

Snowflake Deep Dive: Master Clustering for Peak Performance
Unlock the secrets of table clustering to supercharge your Snowflake queries. Learn how to optimise your data layout for lightning-fast analytics and improved resource efficiency.

This article is part of the Master Snowflake for real-world use playlist. Click here to explore the full series.

Greetings, curious reader,
Many data engineers need help with slow performance and high costs. But there's hope. Clustering can supercharge your Snowflake tables, slash query times, and save money.
I'll show you how to master Snowflake clustering. You'll learn how to choose the right keys, optimise performance, and cut costs. By the end, you'll know how to transform your sluggish warehouse into a lean, data-crunching machine.
Clustering organises your data logically, grouping similar information. This means Snowflake can quickly find and retrieve the data you need without sifting through irrelevant information.
You and I will dive deep into Snowflake clustering, exploring key selection, automatic vs. manual approaches, and advanced techniques. You'll gain the knowledge to implement a rock-solid clustering strategy.
Let's dive in.
Reading time: 10 minutes
Why Clustering Matters in Snowflake
You and I both know that optimising query performance is crucial in any data warehouse. That's where clustering in Snowflake comes into play. It organises table data to improve query performance and reduce computing costs. Well-clustered tables allow Snowflake to quickly locate relevant data, minimising unnecessary scans.
Key benefits of clustering:
Improved query performance: Queries can quickly access relevant data.
Reduced compute costs: Less data scanned means fewer credits consumed.
Enhanced data organisation: Logical grouping of related data.
Without clustering, queries may scan large amounts of irrelevant data, leading to:
Excessive Snowflake credit consumption
Slower reporting and analytics
Inefficient use of computing resources
Clustering acts like a librarian for your data, organising it for quick retrieval. This organisation becomes crucial as your data volume grows and query complexity increases.
The Core of Clustering: What You Need to Know
Defining Clustering in Snowflake
I've written a nice article that explains micro-partitions deeply in an approachable way, using beer as an analogy. If you want to learn more about micro-partitions' intricacies, I highly recommend you check out that article.

Clustering organises table data into micro-partitions based on specified columns. This logical organisation impacts data retrieval efficiency. Snowflake uses these micro-partitions to optimise query processing and data pruning.
When you define clustering keys, you tell Snowflake which columns are most important for your typical queries. This information guides the physical organisation of data within micro-partitions.
Clustering vs. Traditional Partitioning
Snowflake's clustering differs from traditional partitioning in several key ways:
Flexibility: Clustering adapts to data changes without manual intervention.
Granularity: Offers finer control over data organisation.
Automatic management: Snowflake can handle clustering optimisation.
Multi-dimensional: Supports multiple clustering keys for complex data relationships.
Traditional partitioning often requires careful planning and manual maintenance. Clustering, on the other hand, provides many of the benefits of partitioning with less administrative overhead.
Key Benefits of Effective Clustering
Faster query execution: Snowflake can quickly identify and access relevant micro-partitions.
Improved pruning efficiency: Irrelevant data is easily skipped during query processing.
Optimised storage utilisation: While not directly compressing data, clustering can lead to better compression ratios.
Effective clustering can dramatically reduce the data Snowflake needs to scan for a given query. This translates directly into faster query times and lower compute costs.
Diving Deep: The Technical Nitty-Gritty
Clustering Key Selection
Choosing the right clustering key is crucial for optimal performance. Consider these factors:
Single-column clustering: Suitable for simple scenarios with clear filtering patterns.
Multi-column clustering: Ideal for complex data with multiple query dimensions.
Cardinality: High-cardinality columns often make good clustering keys.
Query patterns: Analyse common
WHEREclauses andJOINconditions.Data distribution: Evenly distributed data tends to cluster more effectively.
Example of creating a clustered table:

In this example, clustering by sale_date and product_id would benefit queries that frequently filter or join on these columns. The order of clustering keys matters – place the most commonly used filter column first.
Automatic vs Manual Clustering
Snowflake offers both automatic and manual clustering options:

Pros and cons:
Automatic:
Pros: Less maintenance, continuous optimisation
Cons: Less control, potential for unexpected credit consumption
Manual:
Pros: Full control over the reclustering process, predictable credit usage
Cons: Requires ongoing management, risk of suboptimal clustering if not maintained
Choose automatic clustering for tables with frequent data changes and consistent query patterns. Opt for manual clustering when you need precise control over the reclustering process or have complex, changing query patterns.
The Reclustering Process
Reclustering maintains optimal data organisation as your data changes. Triggers for reclustering include:
Data changes exceeding internal thresholds
Manual initiation
Scheduled maintenance windows

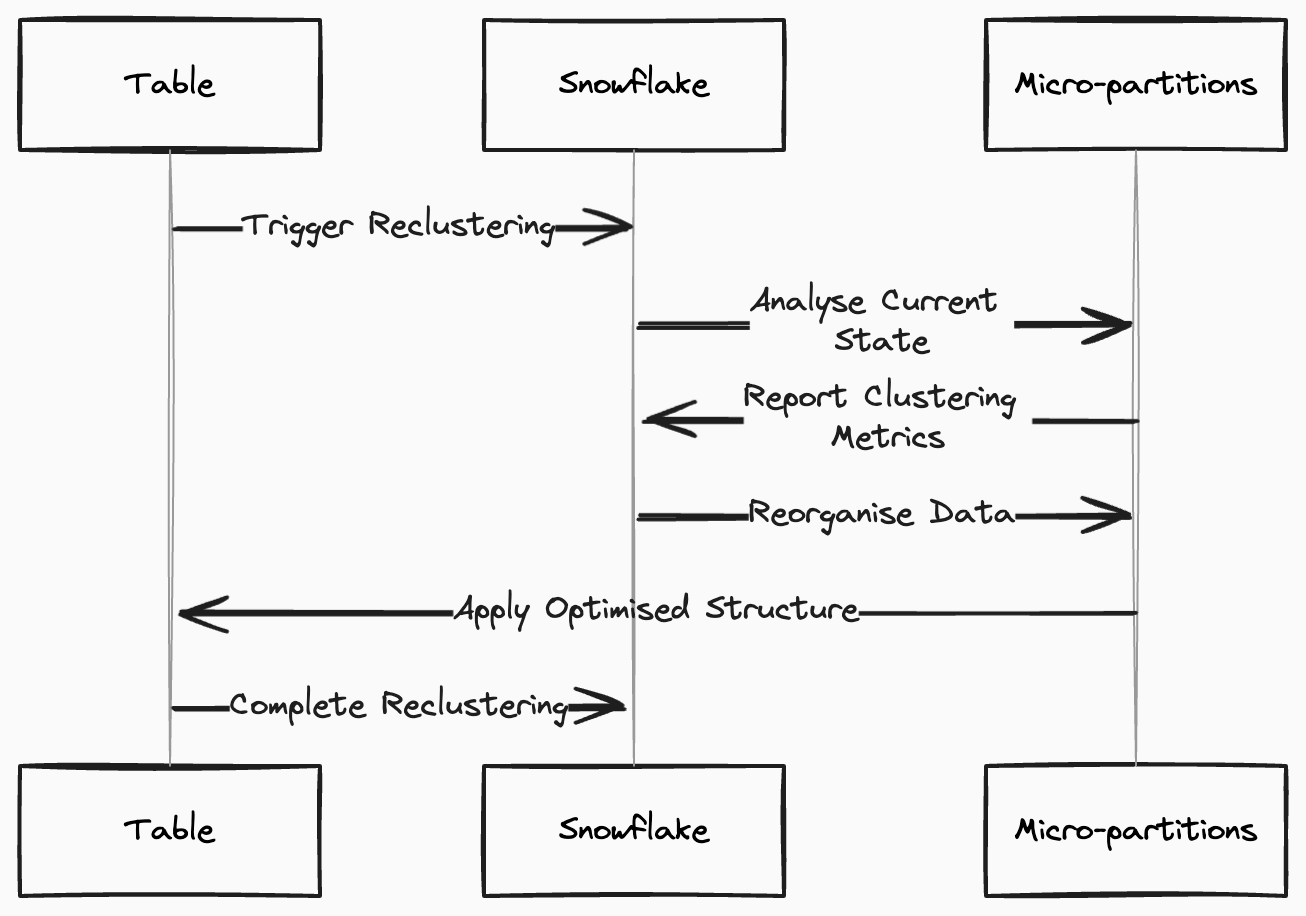
Snowflake reorganises data within micro-partitions during reclustering to optimise for the defined clustering keys. This process runs in the background and doesn't block ongoing queries or data modifications.
Pro Tip: Instead of reclustering the table you really work with, you should clone it and work with the cloned table. That gives you the flexibility to experiment with clusters without breaking your data. We can talk about zero-copy cloning another time, but for now, know it's a powerful tool in your Snowflake arsenal.
Advanced Clustering Techniques
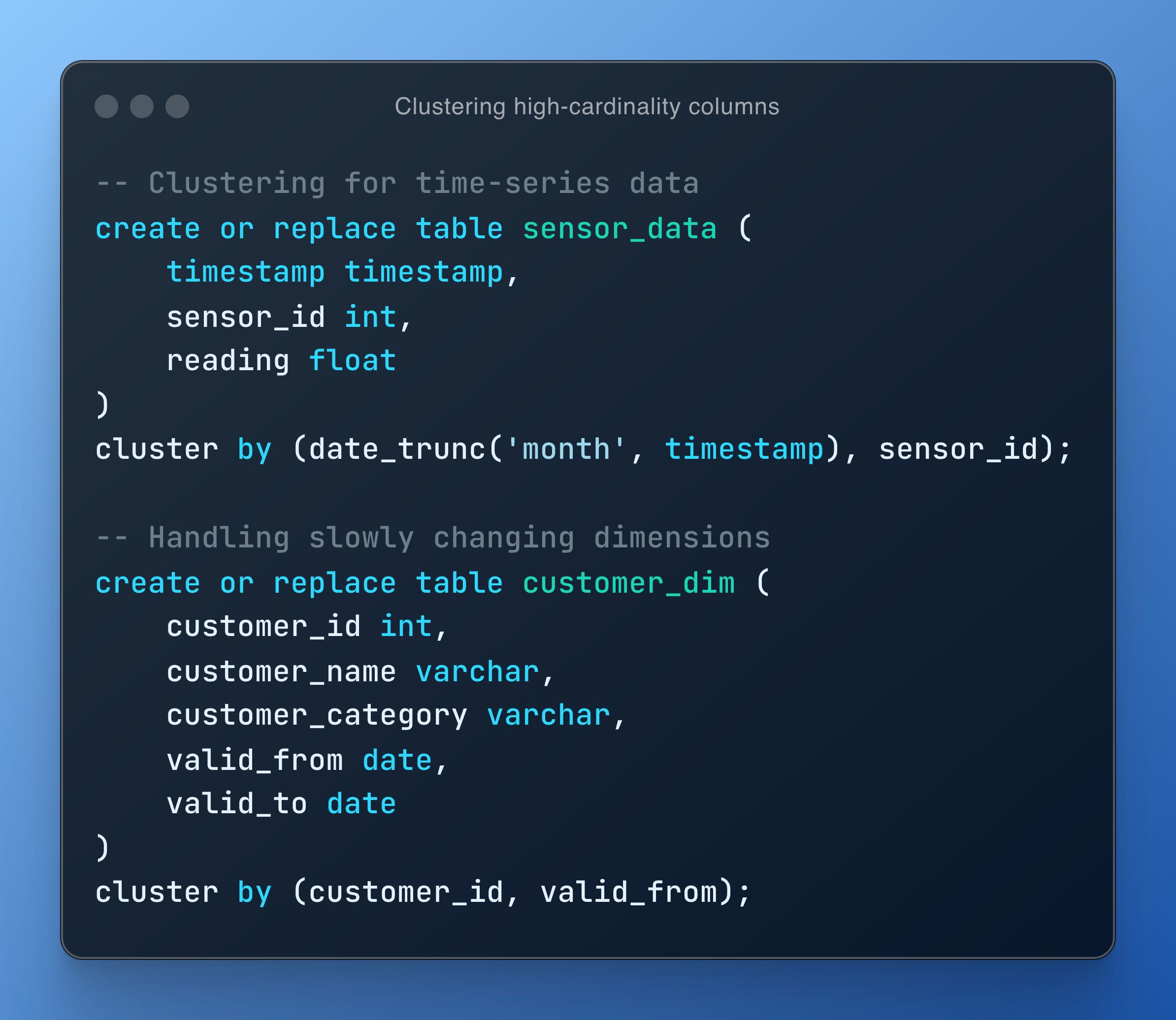
Time-series data clustering:
Combine date/time columns with other dimensions
Consider using truncated date values for more efficient clustering
Handling slowly changing dimensions:
Include version or validity period columns in clustering keys
Balance historicisation and query performance
High-cardinality columns:
Use derived values or substrings for more effective clustering
Combine high-cardinality columns with lower-cardinality ones
Examples:
Rolling window clustering concept:
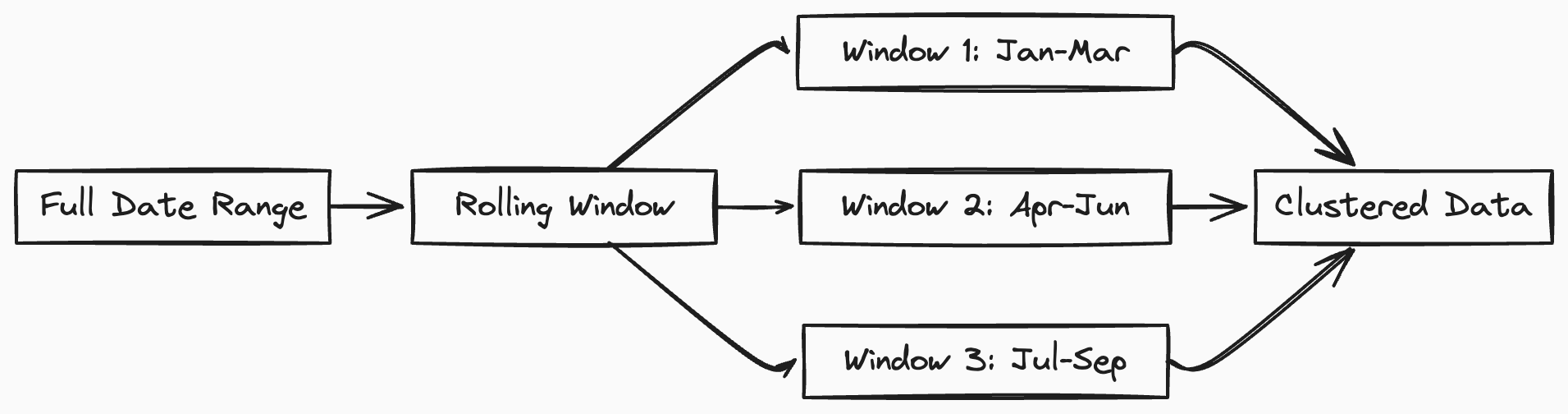
This approach helps manage large time-series datasets by focusing clustering on recent data while maintaining a broader organisation for historical data.
Did you know? I wrote an extensive Snowflake learning guide. You can get it for free today. You only need to share Data Gibberish with 5 friends and coworkers. You will get a 3-month Pro membership to your favourite newsletter as a bonus.
